
در ادامه مسخرهبازیهایی که اخیرا با ابزارهای هوش مصنوعی دارم، به بخش تحلیل متن رسیدم. الان دارم با مدل Word2Vector کار میکنم. این مدل کارش اینه که تعداد زیادی متن رو میخونه، و صرفا از روی محیطی که اون کلمه درش قرار داره، معنای اون رو پیشبینی کنه. (با خود کلمه و حروفش کاری نداره.) البته دقیقا نمیتونه بگه این کلمه چه معنیای داره. اما میتونه کلمات دیگهای که در یک فضای معنایی مشابه اون قرار دارند رو تشخیص بده. مثلا کلمات بد و خوب، با این که متضاد هم هستن، در یک فضای معنایی قرار میگیرن، چون میشه به جای همدیگه استفاده کنیم. (هرچند معنی کاملا عوض میشه، اما جمله بیمعنی نمیشه) حالا که سیستم به این شناخت از کلمات رسید میشه این درک حاصله رو روی تصویر هم نشون داد، جوری که کلماتِ با فضای معنایی مشابه، به همدیگه نزدیکتر باشن.
از اونجایی که این سیستم لازم داره حجم زیادی از متن رو به عنوان خوراک دریافت کنه، با خودم گفتم چه جایی بهتر از وبلاگ محمدرضا شعبانعلی؟ در نتیجه یک خزنده (Crawler) نوشتم که متن تمامی پستها و کامنتهای اونجا رو ذخیره کنه. (مدل سادهی شدهی کاری که گوگل میکنه.) حاصل نهایی کار شد این عکسی که میبینید. چند قسمت خیلی جالب برای من داشت. مثلا سیستم تونسته ضمیرها رو تشخصی بده و کنار هم قرارشون بده. (پایین سمت راست) یا تمامی افعال همخانواده کنار همن. یا کلمات «هرگز» و «اصلا» تقریبا روی هم قرار دارن. همچنین «تنها» و «فقط». و…
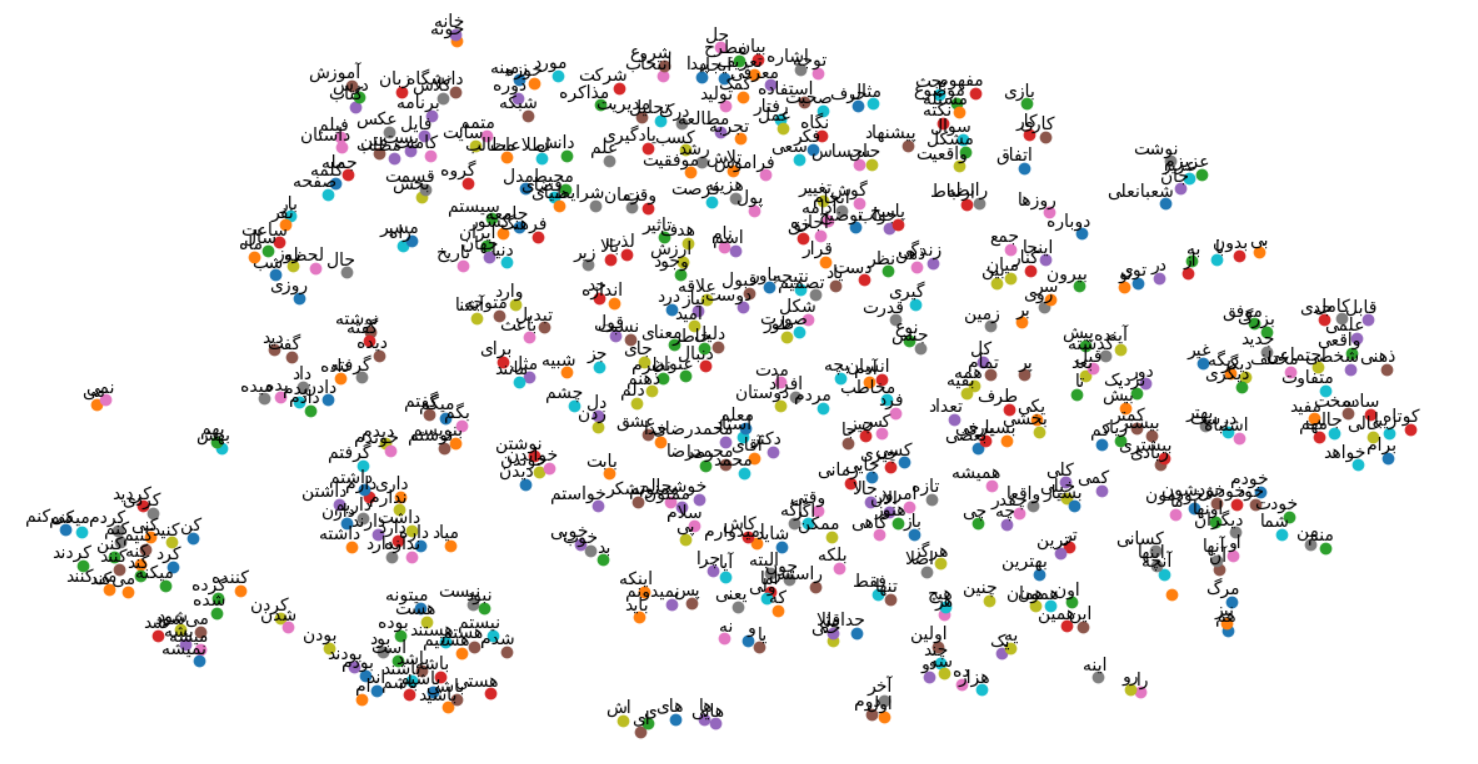
برای شلوغ نشدن عکس، فقط ۵۰۰ تا از کلمات رو توی عکس نشون دادم. برای دیدن در اندازهی بزرگتر، روی عکس کلیک کنید.
پینوشت۱: کلمهی «شعبانعلی» دقیقا کنار «عزیز» و «جان» نشسته. چقدر هم که درسته 🙂
پینوشت: محمدرضای عزیز. در حین خزیدن در وبلاگت، به این نتیجه رسیدم که ظاهرا پست لحظه نگار خودت مشکل داره. حداقل برای من که اصلا نشون داده نمیشه. نمیدونم مشکل از منه یا نه. خواستی یه بررسی بکن.
۹ دیدگاه دربارهٔ «تحلیل محتوای وبلاگ محمدرضا»
سلام
واقعا کار بینظیری کردید
موفق و پیروز باشید
سلام
شما برای این پروژهها از چه زبان برنامهنویسی استفاده میکنید؟
سلام علی جان.
من از زبان پایتون و ماژول تنسور فلو (TensorFlow) استفاده میکنم.
خیلی خوبه که این پست تخصصی رو نوشتی ایمان.آفرین
ایمان
میتونی بگی کدوم کلمات بیشتر از همه تکرار شدن؟
علی جان محاسبهاش کاری نداره. نهایتا ۵ خط کده. اما دیتای محمدرضا توی لپتاپ شرکت هستش و چون میخواستم آخر هفته روی موضوع دیگهای کار کنم، حواسم نبود که اون رو همراه خودم داشته باشم و الان نمیتونم چیزی بگم.
البته جواب بدیهی اینه که اولیها چندتا حرف اضافه مثل «از» و «که» و «و» هستن. اما اگه دنبال کلمات به درد بخور هستی باید تا شنبه صبر کنی.
علی جان، شرمنده از تاخیرم.
این کلمات لیست به ترتیب پر تکرارترین کلمات کل مطالب و کامنتهای محمدرضا هستن:
(‘و’, ۱۵۰۲۷۰), (‘که’, ۱۰۵۵۵۲), (‘به’, ۸۶۱۳۵), (‘از’, ۷۰۲۶۰)
(‘در’, ۶۴۹۹۱), (‘می’, ۶۱۲۷۰), (‘این’, ۵۲۲۸۹), (‘را’, ۳۹۰۸۱)
(‘من’, ۳۴۹۳۰), (‘رو’, ۳۴۷۱۷), (‘با’, ۳۳۳۶۶), (‘هم’, ۳۲۶۵۱)
(‘است’, ۲۳۶۸۰), (‘برای’, ۲۳۵۰۹), (‘های’, ۲۲۳۱۶), (‘یک’, ۱۹۸۱۸)
(‘ها’, ۱۹۷۴۴), (‘یا’, ۱۷۴۰۷), (‘ما’, ۱۶۳۳۵)
عددهای روبروی کلمات هم تعداد تکرارشون در مجموع هستش.
اولین اسمهای معنی دار در ادامهی لیست به ترتیب، «فکر»، «کار» و «زندگی» هستن.
سلام
چه کار جالبی
حس خوبی بهش دارم
ایمان از کی این کار را شروع کردی؟ (کار با هوش مصنوعی)
سلام حمید جان
تاریخ چندان مشخصی نداشت. زمستان ۹۴ اولین آشنایی من با متدهای هوش مصنوعی توی دانشگاه بود که خودت میتونی حدس بزنی نمیشد باهاشون یه کار درست و حسابی کرد. تابستان پارسال اولین پروژهی کاربردیم رو در پردازش تصویر داشتم که پستش رو هم نوشتم. (تشخیص احساسات با هوش مصنوعی) دو ماهی هستش که برای پیشرفت بیشتر به زبان پایتون مهاجرت کردم. دو هفته هم هستش که این کورسی که گوگل منتشر کرده رو مطالعه میکنم. این کورس سعی میکنه که همه حوزههای مهم رو پوشش بده و تازه چند روزه که به قسمت پردازش متن رسیدم.